Graphlix:
A graph visualization of movie landscape
|
Arthur Nishimoto |
Khairi Reda |
Download
Introduction
Graphlix is a visualization of movie recommendations using force-directed graphs. The recommendations are calculated from the Netflix prize dataset which comprises roughly 17,000 movies, and 100 million customer ratings of these movies. A graph shows a set of movies as nodes, with links between a pair of movies indicating that the two movies are similar, and audience who liked on them are likely to enjoy the other.
While movie recommendations are inherently driven by personal preferences of individuals, when a large number of recommendation are combined together and correlated with each other, one could reduce the uncertainty, resulting in recommendations that are likely to be agreeably by a wide variation of audience. Visualizing these recommendations using force-directed graphs could reveal interesting patterns such as clusters of highly connected movies which of some genre, for example.
The visualization
The visualization starts by showing a single movie represented as a node in a graph. When the user double clicks that movie, the top N recommended movies are added to the graph with edges linking the root movies to all its recommendations. The user can repeat this operation indefinitely, exploring the recommendation of the expanded movies. A basic force-directed layout is used to ensure a good layout the minimizes edge crossings, and places highly connected clusters of nodes close to each other.
This implementation of the force-directed graph was based a Processing applet found at http://www.cricketschirping.com/weblog/2005/12/11/force-directed-graph-layout-with-proce55ing/ .
This provided the framework for the graph’s layout as well as the physics model used to connect the nodes and edges. While the original implementation generated a nice force-directed graph, the data structures used in this implementation were designed for a static graph, did not lend themselves well a dynamical graph that changes during runtime.
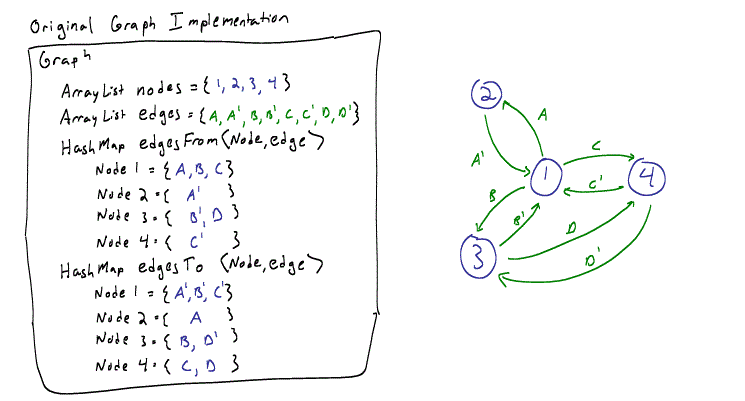
In order to make it easer to dynamically change the graph, I decided that each node needed to be aware what edges it is connected to, so I re-wrote the entire graph, edge, and nodes classes, leaving only the physics structure intact.
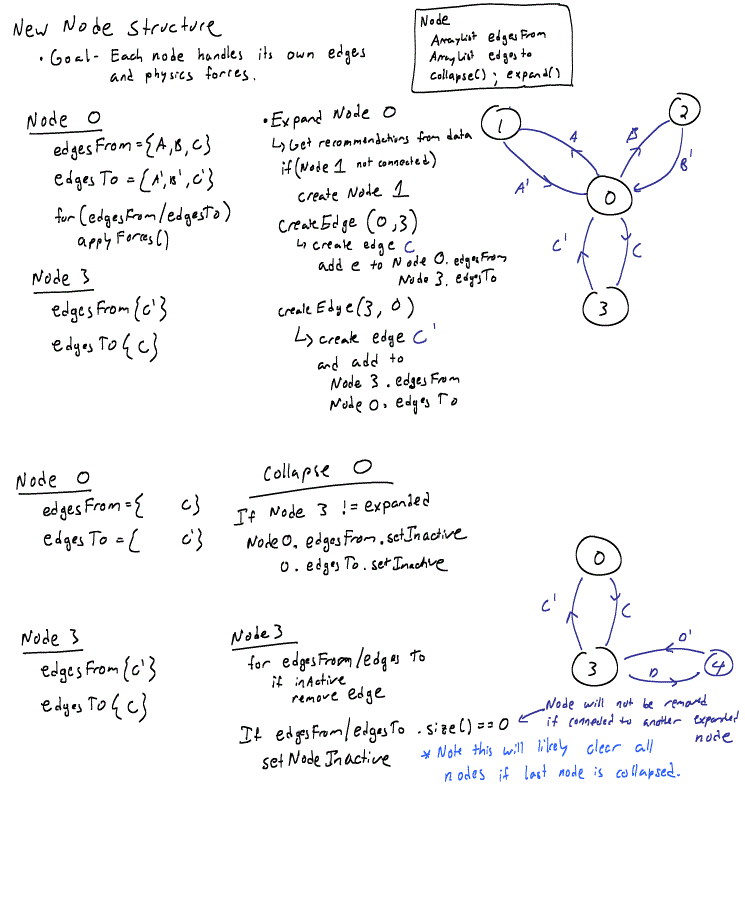 With this structure it was much easier to collapse and expand each node based on the current state of its neighbors. When the user double-clicks on a node to expanded or collapse it, the node itself calls either collapseNode() or expandNode() which creates/removes edges and/or connected nodes as necessary. The two lists, edgesTo and edgesFrom, remain as two separate edges as these are used (as in the original implementation) to create the push and pull forces on each pair of nodes.
With this structure it was much easier to collapse and expand each node based on the current state of its neighbors. When the user double-clicks on a node to expanded or collapse it, the node itself calls either collapseNode() or expandNode() which creates/removes edges and/or connected nodes as necessary. The two lists, edgesTo and edgesFrom, remain as two separate edges as these are used (as in the original implementation) to create the push and pull forces on each pair of nodes.
Interactions

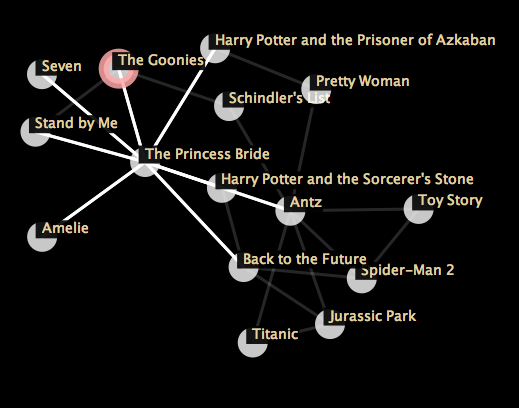
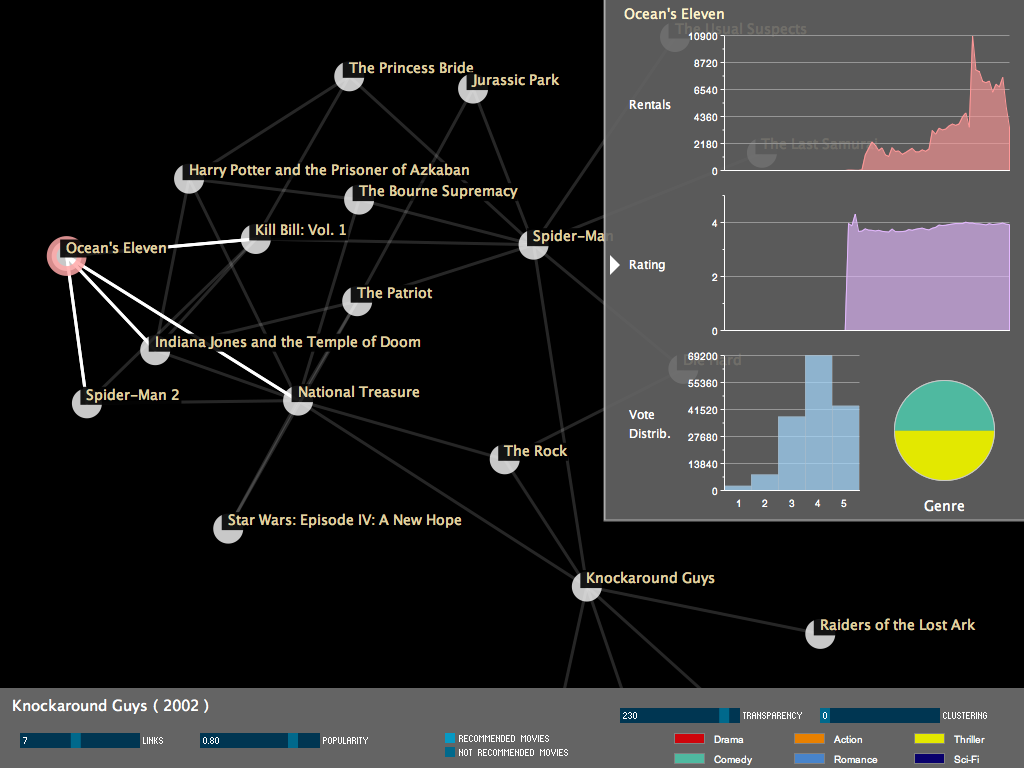
Charts
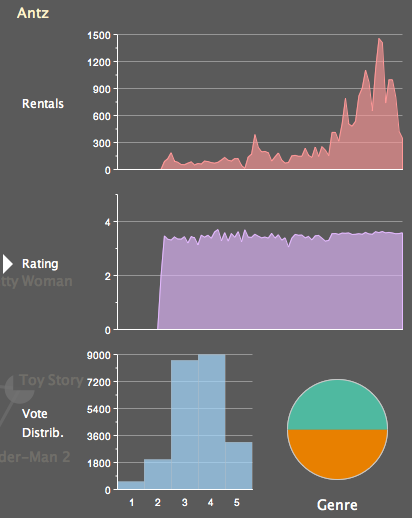
A side chart panel can be shown/hidden by clicking on the arrow in the upper right corner of the application. The chart panel has 4 charts:
Clustering
Exploring the recommendations of movies could be fun. However, it does not give insight into patterns, or does not facilitate easy answers for questions like: what is the shared quality among a collection of movies that form some cluster.
One of the nice things with a force-directed graph is that the algorithm works naturally to produce a layout that places highly connected nodes close to each others, and away from other clusters. Still, it is not always easy for the user to see these clusters without additional visual aides. A clustering feature has been added to allow the user to easily see clusters of mutually recommended movies. This works by adjusting a slider which specifies the number of clusters. Clusters are detected using a K-mean algorithm, and a bubble (convex-hull) is drawn around nodes comprising a cluster, and clusters are colors coded. When the clusters are visualized, the edges of the nodes are not displayed. K-mean implementation was taken from: http://www.sourcecodesworld.com/source/show.asp?ScriptID=807 . Convex-hull computation code partially based on: http://pages.cpsc.ucalgary.ca/~rokne/CONVEX/convex.html

When a cluster is clicked, a pie chart is displayed, revealing the genre distribution of all the movies in the cluster. Multiple clusters can be clicked, revealing the genre distribution of different clusters.

The K-mean clustering scheme implemented here works by clustering the position of nodes, rather than their connectivity. This is certainly not optimal. A better solution would be using hierarchical graph clustering. This was not done due to lack of time. However, in certain situations, as the case with force-directed graphs, K-mean is not that bad as the force-directed layout carries some of the work for clustering interconnected nodes and placing them close to each other allowing the K-mean algorithm to pick up form that.
Data mining
The Netflix dataset contains about 17,000 movies. The first step was to filter these movies a bit and reduce their number. All movies that have less than 2,500 ratings were removed. This was done using a shell script that loops throw all movies (each movie's ratings are in a separate file), determine the number of lines (each rating is on a single line), and deletes the file it has less than 2500 lines. Next step was removing all customers that voted less than 50 times. This was done using Processing in a single pass before the actual parsing process began
Once the data was filtered, the votes were loaded into a matrix (customers vs. movies) and stored into memory. All the movies watched by a single customer were loaded into memory. However, only a list of the first 40,000 customers who watched a certain movie are kept. After the data was loaded, the recommendation generation algorithm was run. The algorithm works as follows:
This algorithm is similar to the following survey-based process. Go to a theater, and start asking the people coming out of a movie to vote for it. Take the customers who really liked the movie, and ask them to list a set of 400 movies that they also really liked. Correlate the lists together and take the most common movies. This of course means the result is skewed towards mainstream movies such as Lord of the Rings. However, popularity slider allows the user to skip the most common correlations and choose ones in the middle of the the 200 entries in the correlation list, for example. To calculate the 'non-recommended' movies, the same algorithm is used, except instead of a vote of '5' in step 2, customers who voted '1' are picked. The idea is pick the customers who really did not like that movie, and look and the movies they liked and pick them as non-recommended.
Last update: nov 11, 09